
自 2017 年横空出世以来,Transformer 模型已经彻底重塑了自然语言处理(NLP)乃至整个人工智能领域的格局。告别了循环神经网络(RNN)和长短期记忆网络(LSTM)的顺序处理限制,Transformer 凭借其创新的 自注意力(Self-Attention)机制,实现了前所未有的并行计算能力和对长距离依赖的捕捉能力。本文将简单介绍这一革命性架构的核心。
“注意力”就够了
Transformer 的核心理念在其开创性论文的标题中昭然若揭:“Attention Is All You Need”。在此之前,处理序列数据(如文本)的主流方法依赖于 RNN 或 CNN。RNN 按顺序处理输入,这使得并行计算变得困难,并且在处理长序列时容易丢失早期信息(即所谓的梯度消失/爆炸问题)。
Transformer 则另辟蹊径,完全基于注意力机制来绘制输入和输出之间的全局依赖关系。它允许模型在处理序列中的每个元素(例如一个词)时,同时“关注”到序列中所有其他元素,并根据相关性计算出该元素的加权表示。
自注意力机制:模型如何“聚焦”
想象一下您在阅读一个句子:“The animal didn’t cross the street because it was too tired.” 当读到 “it” 时,您的大脑会自动将它与 “animal” 联系起来,理解 “it” 指代的是 “animal”。自注意力机制做的就是类似的事情,让模型理解词语之间的依赖关系,无论它们在句子中相隔多远。
为了实现这一点,它为输入序列中的每个元素(词嵌入向量加上位置编码)学习了三种不同的表示形式:
- 查询(Query, Q): 代表当前正在处理的词,它会去“查询”序列中的其他词。
- 键(Key, K): 代表序列中的所有词(包括自身),用于响应查询,与 Q 计算相关性(注意力得分)。
- 值(Value, V): 同样代表序列中的所有词,最终根据计算出的注意力得分进行加权求和,得到当前词经过注意力机制处理后的新表示。
这通常通过将输入向量 $X$ 分别乘以三个在训练过程中学习到的权重矩阵 $W^Q, W^K, W^V$ 来得到 $Q, K, V$ 矩阵。
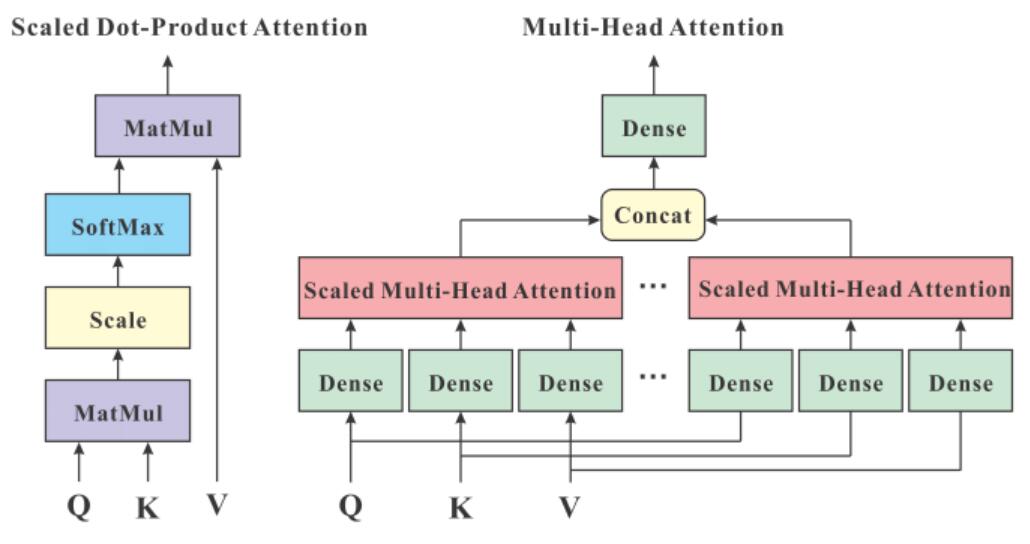
最常用的注意力计算方式是缩放点积注意力 (Scaled Dot-Product Attention),其计算公式如下:
\[\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V\]这里的 $d_k$ 是键(Key)向量的维度。计算 $Q$ 和 $K$ 的转置 ($K^T$) 的点积,得到它们之间的原始注意力分数。除以 $\sqrt{d_k}$ 是一个缩放因子,目的是为了防止点积结果过大,导致 softmax 函数的梯度变得极小,从而影响训练稳定性。softmax 函数将这些分数转换成概率分布(即注意力权重),表示每个词应该对当前词的表示贡献多少“关注度”。最后,将这些权重乘以对应的值(Value)向量 $V$ 并求和,就得到了该位置经过注意力加权后的输出向量。
import torch
import torch.nn as nn
import math
class ScaledDotProductAttention(nn.Module):
"""计算缩放点积注意力"""
def forward(self, q, k, v, mask=None):
dk = k.size()[-1] # 获取 Key 向量的维度
# 计算 Q 和 K^T 的点积
attention_scores = torch.matmul(q, k.transpose(-2, -1))
# 除以 sqrt(dk) 进行缩放
attention_scores = attention_scores / math.sqrt(dk)
# 应用 Mask
if mask is not None:
# 将 mask 中为 0 的位置设置为一个非常小的负数
attention_scores = attention_scores.masked_fill(mask == 0, -1e9)
# 计算 softmax 得到注意力权重
attention_weights = torch.softmax(attention_scores, dim=-1)
# 将权重应用于 V
output = torch.matmul(attention_weights, v)
return output, attention_weights
# q, k, v 是已经准备好的 Query, Key, Value 张量
# attention_layer = ScaledDotProductAttention()
# output, weights = attention_layer(q, k, v)
Transformer 的一个巨大优势在于,上述所有计算都可以高度并行化,因为每个位置的注意力计算不依赖于前一个位置的计算结果(与 RNN 不同),这极大地加速了模型的训练过程。
多头注意力:从不同角度理解
单一的注意力机制可能只关注到一种类型的相关性。为了让模型能够从不同的“角度”或表示子空间(representation subspaces)捕捉信息,Transformer 引入了多头注意力(Multi-Head Attention)。
简单来说,就是并行地运行多个独立的缩放点积注意力计算单元(称为“头”)。每个头都有自己独立的 $W^Q, W^K, W^V$ 权重矩阵。输入向量首先被分别投影到多个较低维度的 Q, K, V 空间(每个头一个空间),然后在每个空间内独立计算注意力。最后,将所有头的输出拼接(concatenate)起来,再通过一个最终的线性层进行融合,得到多头注意力的最终输出。
这种机制使得模型能够同时关注不同位置、不同类型的依赖关系。例如,一个头可能关注语法结构,另一个头可能关注语义关联。
整体架构:编码器与解码器
标准的 Transformer 模型采用经典的编码器-解码器(Encoder-Decoder) 架构,这在机器翻译等序列到序列任务中非常有效。
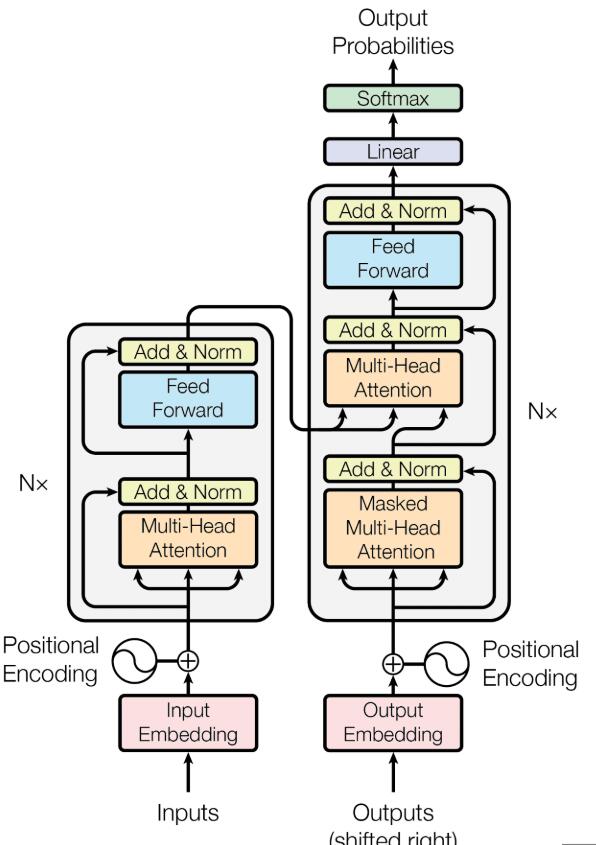
编码器(Encoder) 部分由 N 层相同的层堆叠而成。每一层主要包含两个子层:一个多头自注意力层(让输入序列中的每个词关注序列中的其他词)和一个简单的、按位置独立应用的全连接前馈网络(Position-wise Feed-Forward Network)。每个子层之后都跟着一个残差连接(Residual Connection)和层归一化(Layer Normalization),这有助于缓解深度网络的训练难度并加速收敛。编码器的目标是将输入序列(例如源语言句子)转换成一系列富含上下文信息的向量表示。
解码器(Decoder) 部分也由 N 层相同的层堆叠而成。与编码器层类似,但也略有不同。解码器的每一层包含三个子层:
- 带掩码的多头自注意力层 (Masked Multi-Head Self-Attention):这里的自注意力与编码器类似,但是增加了一个“掩码”(Mask),确保在预测当前位置的词时,只能关注到当前位置及之前的位置,不能“看到”未来的词。这是为了维持生成过程的自回归(auto-regressive)特性。
- 多头注意力层 (Multi-Head Attention):这一层的 Query 来自前一个解码器子层的输出,而 Key 和 Value 则来自编码器的最终输出。这使得解码器在生成每个目标词时,能够关注到输入序列的所有相关部分。
- 位置全连接前馈网络 (Position-wise Feed-Forward Network):与编码器中的相同。 同样,解码器的每个子层也都有残差连接和层归一化。
在输入文本进入编码器或解码器之前,它们会先经过词嵌入(Word Embedding) 层,将离散的词语转换为连续的向量表示。由于自注意力机制本身不包含位置信息,模型还需要位置编码(Positional Encoding)。这些位置编码向量会被加到词嵌入向量上,为模型注入关于词语在序列中绝对或相对位置的信息。